Case Study : Ronnies' Riveting Reads
Tiffany Moye
08/31/2022
Table of Contents:
Summarize
Ask Phase
- Business task
Prepare Phase
- Dataset used
-Accessibility and privacy of data
-Information about our dataset
-Data organization and verification
-Data credibility and integrity
Process Phase
-Installing packages and opening libraries.
-Importing datasets
-Preview our datasets
-Cleaning and formatting
Analyze and Share Phase
Books with the highest user rating.
Books with the most reasonable pricing.
Good Variety of novels for customer base to choose from.
Correlations
Act Phase
-Conclusion
SUMMARY
Ronnies’ Riveting Reads is a brand new bookstore that produces many of amazon's best selling novels. They offer different genres such as fiction and nonfiction, they even have a wide selection of books for all different age groups!
The most imperative aspect we want to focus on with this study is showcasing the bookstores most popular reads in order to get more patrons entering the store on opening night. In this case we will be focusing on the top 3 books to include on Ronnies Riveting Reads’ display shelves.
ASK PHASE
Business Task: Identify the top 3 best selling novels from amazon that will bring us the most amount of new patrons, so that they can be showcased on opening night.
Stakeholders:
Jed Williams (boss at business intelligence firm, who made me lead in this case)
Ronnie’ Brown (Owner of Ronnies’ Riveting Reads)
Marketing Analytics team (business intelligence firm)
PREPARE PHASE
Dataset Used- The Dataset used in this case study is Amazon's top 50 best selling books 2009-2019. This dataset is stored in kaggle and made available by Souter Saalu .
ACCESSIBILITY AND PRIVACY OF DATA.
Verifying the metadata of our dataset we can confirm it is open-source. The owner has dedicated the work to the public domain by waiving all of his or her rights to the work worldwide under copyright law, including all related and neighboring rights, to the extent allowed by law. You can copy, modify, distribute and perform the work, even for commercial purposes, all without asking permission.
INFORMATION ABOUT OUR DATASET
These datasets were generated by a respondent who gathered data off of amazon.com to come up with users favorite reads. Respondent also managed to group novels based on genre!
DATA ORGANIZATION AND VERIFICATION
Available to us is 1 csv file, 550 rows and 7 columns. This data is considered long due to the fact that it has more rows than columns.
Due to the small sample size , I decided to use google sheets to sort and filter my data by using pivot tables. I was able to verify attributes and observations of each table and relations between tables.
DATA CREDIBILITY AND INTEGRITY
Due to the fact that Amazon is one of the top ecommerce platforms; there are millions of users on Amazon a day. This means that our data is unbiased because of our large sample size. However, we would have a problem with the fact that the data is out of date. The last time it was updated was in 2020 so we would have to use an operational approach.
PROCESS PHASE
I will focus my analysis in R due to its accessibility, and the amount of data. However, I will be using Tableau to visualize my findings and share them with my stakeholders, due to the fact that Tableau is a more interactive platform.
INSTALLING PACKAGES AND OPENING LIBRARIES
Tidyverse
Here
Skimr
Janitor
Lubridate
Ggplot2
Dplyr
IMPORTING DATA SETS
We will upload the datasets that will help us answer our business task. On our analysis we will focus on the following dataset:
Bestsellers with categories.csv.xls
rename(bestsellers_with_categories.csv.xls) -> best_selling_books
PREVIEW DATASET
Head(best_selling_books)
Str(best_selling_books)
Glimpse(best_selling_books)
Colnames(best_selling_books)
CLEANING AND FORMATTING
After glancing over the dataset, it was time to clean and process It.
Check the data for duplicates and remove them.
Check for null values and remove them.
Clean and rename columns.
Make sure dates and times are consistent.
ANALYZE & SHARE PHASE
We will analyze the trends for Amazon bestselling novels from 2009-2019, in order to help us choose the right books to display for Ronnie Brown in his new book store on its grand opening day.
AMAZON'S BEST SELLERS USER RATINGS
Because the amazon website has an option for customers to leave a rating after trying a product from their website, we are able to better understand how customers enjoy, or don't enjoy what they have purchased. We noticed that this dataset had ratings ranging from 3.3 all the way up to 4.9. Because we know that Mr.Brown is only looking for the books that would gain him the most revenue, we’ve decided to break down the dataset to novels with only a rating of 4.9 and better.
Name of bestseller.
Author of bestseller.
Rating of bestseller.
First, I arranged my dataset by User Rating in descending order.
Bestselling_books2 <- Bestselling_books %>% arrange(-`User Rating`)
(This function allows rstudio to create a data frame where User Ratings are in order from highest to lowest.)
After this I viewed my new table labeled bestselling_books2.
View(bestselling_books2)
I Finally filtered my data to show only User Ratings with a value of “4.9”
bestsellers_new <- Bestselling_books2 %>%
filter(`User Rating` == "4.9")
This left me with each novel on amazon's bestseller list that has a rating of 4.9, which was the highest rating available.
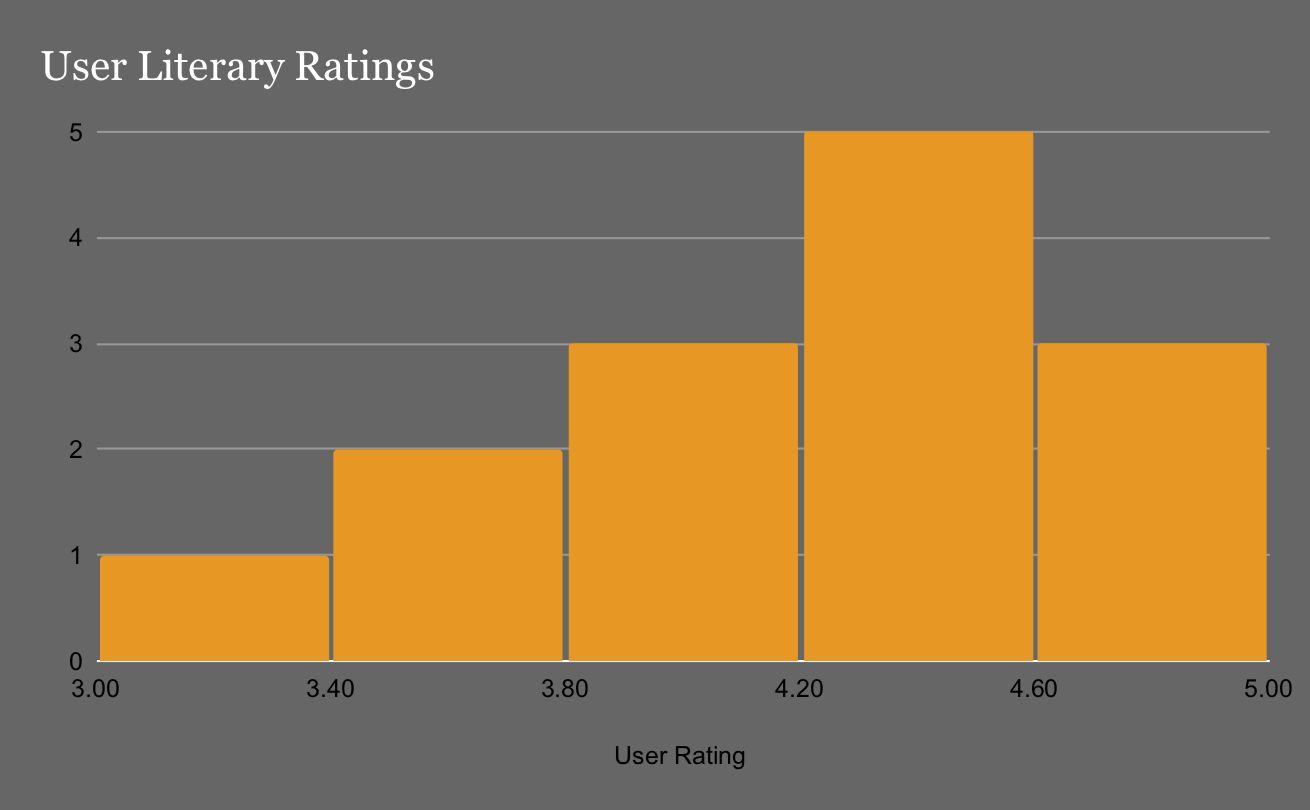
This visualization’s purpose is to show the trends in bestselling book data. Our new data frame, now containing 52 rows showcases that most customers rate on the higher scale. Now that we know that, we have to move to the next step.
AMAZONS REVIEWS
First, I took note of our new dataframe (bestsellers_new.) I noticed that we couldn't make a determination on which books to showcase at Ronnies’ Riveting Reads, so we needed to take it a step farther. We decided to look for the novels with the highest ratings and the most reviews. Why? Because the more people leaving a review for a novel means that more people are reading it. Mr.Brown requested that we choose 3 books that will bring in the highest number of new customers.
After taking note of our new dataframe, we dived into google sheets, where we imported our bestsellers_new table. Because the table only had 52 rows, and the user ratings were all the same, manipulating data became easier.
We then created a pivot table where we sorted our data out, showcasing the names of the bestsellers next to their number of reviews.
We ordered them into ascending order displaying the lowest number of reviews to the highest number.
Finally, we created our visualization using Tableau.

BUT before we could look over our data once more to come up with insights to help Mr. Brown achieve success on his opening night, we had to look at one more aspect.
PRICES OF BESTSELLERS
What makes an opening night a huge success is reasonable prices! Patrons love to go into a store to see their favorite products on the shelves especially when they have enough money in their back pockets to purchase them! We decided that pricing would play a huge part in Mr.Brown achieving the turnout he expected.
First, we opened up our google sheets, to our bestsellers_new table. This table is our condensed dataframe that we created using Rstudio.
After opening our google sheets we then created a pivot table to filter out all the data that had nothing to do with pricing, name, or author.
If any books were priced higher than 25 dollars, they were excluded. Even though they received high ratings and reviews, the price wasn’t ideal for attracting the most amount of patrons to his book store for opening night.
I used the conditional formatting function under the format option in google sheets and I highlighted all novels that exceeded the $25 dollar mark.
Finally, after taking a look over our data we came up with a list. We noticed that a lot of the best sellers on the list were childrens books. This became a problem because Mr. Brown wanted to make sure the most amount of patrons would be enticed to come into his store on opening night. Now if you look at the list of the most popular sellers, with the most reviews which are the cheapest then you will notice that they are children's books. Unfortunately children's books arent indicative of the whole society. In order to bring in the highest amount of paying customers we need a wider selection of books, books that pertain to any and everyone.

Now we finally had enough information to decide on which novels to choose from.
CONCLUSION (ACT PHASE)
Ronnies’ Riveting Reads mission is to empower the community by delivering amazing, relatable, reasonably priced books to citizens.
In order for us to accurately respond to our business task and help Mr.Brown out on his mission, based on our findings, I would suggest Mr. Brown Display Harry Potter and the Goblet of Fire ($18), Oh the places you'll go ($8), and Obama: An Intimate Portrait($22). These three novels reach 3 different types of audiences, they don't exceed the $25 mark, and they are on Amazons list for most popular reads; which in turn will allow Mr.Brown to obtain the highest turnover rate on his opening night.
Each of these bestselling novels bring something different to the display Mr.Ronnie wants to showcase them on. First, each novel is rated as a 4.9 out of 5 on amazon.com and each novel has over 9,000 reviews. In addition to that, each novel has a different genre which opens up the audience pool. Mr. Ronnie will have a book up displayed for Adults, Adolescents and children , so whoever walks through his doors on opening night will be taken care of.
Ronnie’s Riveting Reads will meet and exceed their metric goals if they follow our recommendation to show case, Harry potter, Oh The places you'll Go and Obama: An Intimate portrait.
Dataset used : https://www.kaggle.com/datasets/sootersaalu/amazon-top-50-bestselling-books-2009-2019
Comments
Post a Comment